Thin and Graphy
Normal disclaimer – this is not GraphQL. This is me making stuff up based on a 30 minute conference talk and a gist – and now a tweet!
I spent 10 days working on an implementation of GraphQL queries using Prismatic Graph. It didn’t really work out through no fault of the library but due to my misuse of the library. I started to write up what I had done and found myself writing pseudo code to explain the actual working code and that seemed like a bad sign. “Pretend this code looked like this much more obvious and explainable code – thats what it does”.
Then Nick Schrock posted a screenshot of a GraphQL mapping file with the comment:
Key takeaway is thinness of this file

This turned my doubt of whether my current attempt at an implementation was good into outright disgust at the code I had written.
So I threw it away and started over.
One of the things I struggled with is separating API’s. For my example I’m using the Github API which is an HTTP / REST API. I’m going to write some amount of code which is a client of this API and then I’m going to write some amount of code which is a GraphQL mapping onto that client code. I kept letting these two things mix. GraphQL was being responsible for too much – it was not thin.
If you look at the mapping file you’ll see the code:
protected function phpType(): string {
return 'EntBootcampPet';
}This refers to the already existing and working internal Facebook API. It can live fully on its own oblivious to the existance of GraphQL. At least that is what I tell myself.
Then you have the field definitions:
protected function fields(GraphQLFieldDefiner $fd): array {
return array(
'name' => $fd->String('getName')
)
}This maps what GraphQL exposes externally – name – to the internal representation – getName. It doesn’t care if that works over HTTP or SQL or Mongo or a CSV file. That is the job of EntBootcampPet.
Again, just a guess.
This keeps it thin – it just needs to know how to get from point A to point B.
Instaparse!
I had previously put off writing a parser. I don’t know how to write a parser. I don’t know what a Context Free Grammer is or anything of that sort. But I decided to take a look at Instaparse over lunch last week. Instaparse is a library by Mark Engelberg used to create parsers in Clojure(Script).
It is amazing.
I love it.
I followed along with the readme during lunch – about 1 hour. The readme is great. Everytime I got through a section and thought up a question the next section immediately answered.
I got home and within the hour I was able to turn this:
Nodes(1, 2) {
name,
id,
link(desktop),
birthday {
month,
year
},
friends.after(20).first(10) as amigos {
count,
edges {
cursor,
node {
name,
location
}
}
}
}
into this:
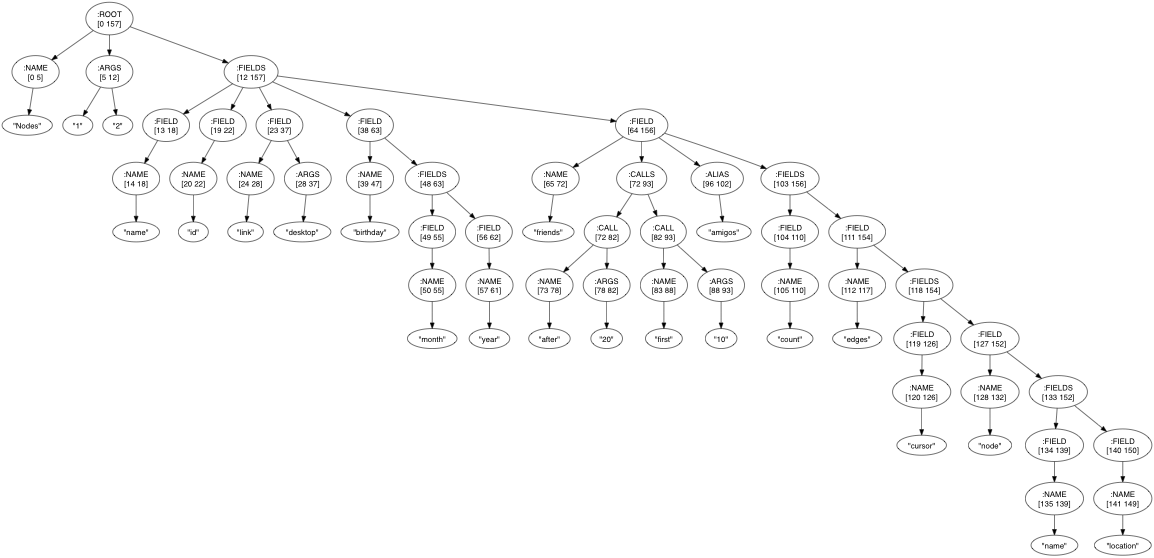
The library is truly awesome. It also works on ClojureScript so I can eventually do those cool Relay demo things and merge queries and stuff on the clientside. Booyah.
For full disclosure here is the syntax I came up with:
ROOT = <whitespace> NAME ARGS? FIELDS <whitespace>
NAME = token
ARGS = <whitespace> <'('> ARG (<','> ARG)* <')'> <whitespace>
<ARG> = <whitespace> token <whitespace>
FIELDS = <whitespace> <'{'> FIELD (<','> FIELD)* <'}'> <whitespace>
FIELD = <whitespace> NAME(ARGS | CALLS)? <whitespace> (<'as'> <whitespace> ALIAS <whitespace>)? FIELDS? <whitespace>
ALIAS = token
CALLS = CALL+
CALL = <'.'> NAME ARGS
<token> = #'\\w+'
whitespace = #'\\s*'My tip to aspiring parser writers – when it doesn’t work keep adding <whitespace> until it does.
Graphs
One of the nice things about my previous implementation (even though it sucked) was that it had an honest to goodness graph with nodes and edges. I wanted to keep that idea. I found this writeup behind the library: rhizome by Zach Tellman very enlightening around representing graphs using immutable data structures in Clojure.
I started with the following:
(def github-graph (-> {:nodes {} :edges {}}
(add-node 'Organization)
(add-edge 'Organization :login :one 'string :login)
(add-edge 'Organization :id :one 'integer :id)
(add-edge 'Organization :name :one 'string :name)))And ended up with this:
(graph/defnode Organization
(field :login 'string :login)
(field :id 'integer :id)
(field :name 'string :name)
(field :repositories 'Repositories (fn [org]
{:url (:repos_url org)
:count (:public_repos org)})))
(def github-graph (-> graph/graph
(graph/add-node Organization)))But really, they are just the same thing. A type is a ‘node’ and a field is an ‘edge’ between two nodes (types) with an executor function. I should really go back and make the ‘node’ and ‘edge’ names ‘type’ and ‘field’ … but it really helped me start off thinking about them in graph terms.
The equivalent of my phpType is just a clojure map of the organization response from the Github API.
{
login: "facebook",
id: 69631,
url: "https://api.github.com/orgs/facebook",
description: "We work hard to contribute our work back to the web, mobile, big data, & infrastructure communities. NB: members must have two-factor auth.",
name: "Facebook",
location: "Menlo Park, California",
// ... snip ...
}Also, as a reminder, keywords are functions in clojure which makes simple getters nice to write.
(:name {:name "Facebook", :id 4729, :login "facebook"}) ;=> "Facebook"At this point I have a parsed query tree and a graph of types and fields with each field having an executor function. I now want to do a joint traversal of the query tree and graph executing each field on the way.
I have hard coded the root call but an example traversal would look like the following:
(let [edge {:type 'Organization
:executor name->organization
:cardinality :one}
query (parse-query "Organization(facebook) { id, name, login, created_at { month, year, format(YYYY-MM-dd) } }")]
(expand github-graph edge query "facebook"))
;;=> {:name "Facebook" :login "facebook" :id 69631 :created_at {:year 2009 :month 4 :format "2009-04-02"}}expand is the function which does the walk (maybe walk is a better name … I suck at naming). For the graph our starting point is an edge from name to Organization with the executor function name->organization. The starting point for the query is the root of the parsed query tree.
(defn expand [graph edge query input]
(let [type (:type edge)
value (execute edge query)]
(if (or (nil? value) (scalar? graph edge))
value
(condp = (:cardinality edge)
:one (into {} (map (fn [field]
[(field-key field) (expand graph (field-edge graph type field) field value)])
(:fields query)))
:many (map (fn [value]
(into {} (map (fn [field]
[(field-key field) (expand graph (field-edge graph type field) field value)])
(:fields query)))
value))))))This ends up being the meat of the implementation. The actual code isn’t that important – it is just worth noting that the joint walk is very little code. This handles scalars, complex objects, one to many’s, fields which take arguments (e.g. format(YYYY-MM-dd)), etc.
Execute
The execute method is kind of interesting. When we parse a query like “created_at { format(YYYY-MM-dd) }” we create a field which has arguments attached to it.
{:name :format
:args ["YYYY-MM-dd"]}Execute then applies these arguments to the edge’s executor.
(defn execute [path edge query input]
(let [args [input]
args (if-let [query-args (:args query)]
(concat args ((:parse-args edge) query-args))
args)]
(apply (:executor edge) args)))The executor in this case is a function which takes two arguments. We use the clj-time library to turn the datetime into a string with the provided format.
(graph/defnode DateTime
;; ... fields for day, month, year, etc ...
(field :format 'string (fn [dt format-string]
(let [formatter (f/formatter format-string)]
(f/unparse formatter dt)))
:args [s/Str]))The first argument is the value generated while running the query – for example the organization’s created_at field – while the second argument is the one parsed out of the query itself – the “YYYY-MM-dd” format string.
These query arguments are also validated and coerced via a schema. The schema for format happens to be a single string. If instead it was an integer the parse-args function would have noticed this executor expects an integer and converted the string representation returned by the query parser into an integer or thrown an exception if it was not convertable. This is done via Prismatic Schema Coercion.
For whatever reason these function fields also make me think about internationalization. I mean, I think the entirety of GraphQL would be great for internationalization. It kind of sucks having to duplicate code on the server and client and then you don’t want to send every language file for your entire application to the client. If you take the Relay type approach you can have each component declare which language keys it depends on – even those which might take parameters. You can then query a language key node via GraphQL and get back just the translated text you need in the language you care about – and no more.
One to Many
For one to many I don’t do anything special – I just make a few more nodes.
(graph/defnode Repositories
(field :count 'integer :count)
(field :edges 'RepositoryEdge (fn [rs]
(gh/url->repositories (:url rs)))
:cardinality :many))
(graph/defnode RepositoryEdge
(field :cursor 'integer :id)
(field :node 'Repository identity))
(graph/defnode Repository
(field :id 'integer :id)
(field :name 'string :name)
(field :full_name 'string :full_name)
(field :description 'string :description)
(field :created_at 'DateTime :created_at))The only real difference is that the field :edges is marked with a cardinality of :many.
Filters are not implemented. E.g. friends.first(10) or friends.after(12345). There is nothing stopping this implementation from doing filters – just add them to the executor function. I just have some outstanding questions I need to think about on how I want to do filters.
Basically I am curious around how special to treat first and after. It seems like making these two special cases would make my life way easier.
Enter Manifold
In order to be cool nowadays you can’t block. The version of expand I showed above is actually not what I use anymore – it was blocking. Each executor that made an http call would block the traversal until the call finished.
Instead I now use the Manifold library which has a Deferred implementation (think javascript promises). I also use Aleph for making non-blocking HTTP requests which return a Manifold Deferred. Both of these are by Zach Tellman – a gentlemen and a scholar I do say.
Since we are traversing a tree we can just call each branch in parallel all the way down. Manifold has this nice let-flow construct which turns callback code into synchronous looking code (think await or go blocks) … but I didn’t use it because I’m lazy. So instead the part of expand that calls each branch in parallel looks like:
(defn expand-fields [graph executer path type fields input]
(let [kvs (map (fn [field]
(let [edge (field-edge graph type field)]
(d/chain (expand graph executer (conj path (field-key field)) edge field input)
(fn [value]
[(field-key field) value]))))
fields)]
(d/chain (apply d/zip kvs) (fn [kvs]
(into {} kvs)))))We call expand on each field and it returns a deferred immediately. We then zip them together (like a javascript when(promise1, promise2, promise3, ...)) and turn them into a map. This function also returns a deferred.
Deferreds all the way down.
Middleware
One other notable thing in the non-blocking version is that we have two new parameters – executer and path. Since we have a single place where we call each edge’s execute method it makes it easy to wrap this in middleware. That is what the ‘executer’ function is – middleware passed through the graph traversal. Path then is just something which tracks how deep in the tree traversal you are – it is purely for logging / diagnostic purposes.
This allows the creation of a middleware function which profiles each execute method along with the path.
(defn profiled-executor [data next]
(fn [path edge query input]
(let [start (/ (System/nanoTime) 1000000.0)
result (next path edge query input)]
(d/chain result (fn [x]
(let [end (/ (System/nanoTime) 1000000.0)
duration (- end start)]
(swap! data assoc path {:start start :end end :duration duration}))))
result)))When we run a graph we get back the profiled execution.
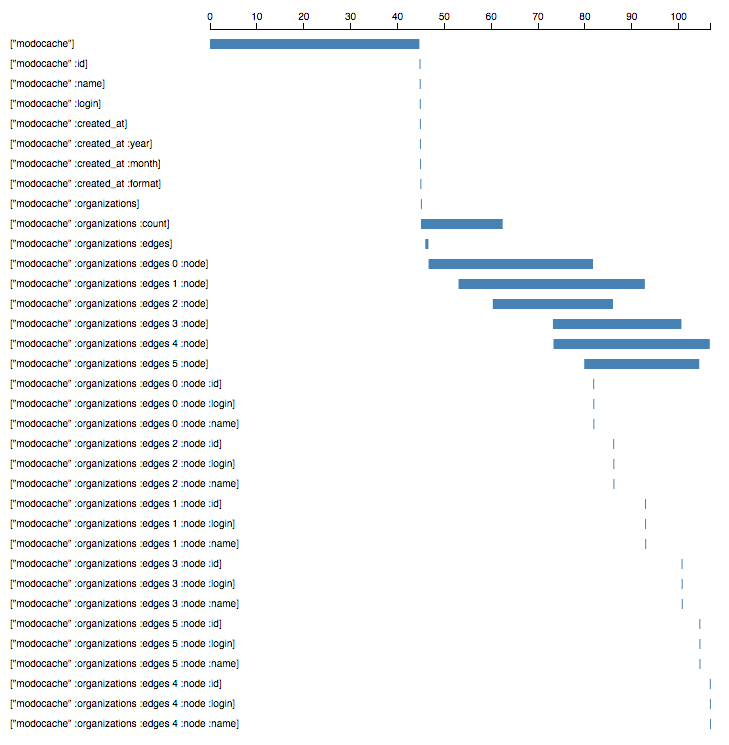
As you can see each organization along with their count is fetched in parallel. They all serially wait on the root fetch of modocache because they depend on the user response.
Putting it Together
Another huge inspiration for all of this was Robert Mosolgo’s work on GraphQL. He has an amazing implementation up and running where you can type in queries and explore the schema using the __type__ field. It is so awesome.
I wanted to try something like that so I made this guy. It isn’t as cool but what can you do! Very few fields and roots work and so I wouldn’t expect anything beyond the initial demo query to return anything. Just make sure you scroll down and see the profile graph – it is my favorite part.
The implementation right now is basically my thoughts as they came to me mashed into emacs. There are a lot of names I want to change and protocols I want to add to clean up the execution.
When I first started writing Clojure I felt like I couldn’t really just sit down and type code – I had to think up front on what I wanted to do. I justified this as forcing good design and Hammocks and stuff … but this past week has basically been me at a 1000 line clojure file with a REPL exploring ideas with horrible, horrible code. I don’t know if this signifies progress or regression in my Clojure abilities …
Exploring the schema with the __type__ construct is so powerful. I immediately started using it on Robert’s demo to see what type of queries I could write. I need to add that.
I had previously wondered how Facebook handled Node being their root call for damn near everything. Then while writing this post I noticed the fields on their GraphQL definition is a function – not static. I wonder if that is how – they can’t statically tell which fields a Node might have in their graph but as they expand / execute the graph they can build it out using the fields function. That wouldn’t work for me – the fields and types are defined up front. Food for thought.
So yah, another week, another stab at GraphQL. Good times.